作为Affiliate来说,当我们谈论SEO时候,默认都是针对国外Google的搜索引擎。
当网站被搜索引擎索引时,搜索引擎蜘蛛(GoogleBot,Yahoo Slurp,Bingbot)会去“抓取”你的网站内容,通过强大的算法辨别你的内容质量、标题、关键词等,如果符合搜索引擎的要求,就会收录进索引库里以便其它人在搜索关键词的时候可以找到你的网页。
但是,如果你的网站部分不希望被搜索引擎编入索引呢?机器人只是单纯的索引它可以找到的内容 – 他们不知道你的网站哪些需要收录,哪些不希望被搜索到,例如,你网站的隐私政策一般是不索引的,或者网站中有某些页面确实不希望被放到网上的内容。在这篇文章中,我们来看看
如何正确使用Robots.txt – 告诉搜索引擎收录哪些页面
什么是robots.txt文件?
Robots.txt其实就是一个文档文件,通常在你网站的根目录,它可以告诉“机器人”,你的网站哪些页面可以访问和无法访问。当这些“机器人”访问您的网站时,它首先要去找robots.txt文件。搜索引擎会根据你文件的要求设定,询问可以访问页面目录有哪些。
如何制作robots.txt文件?
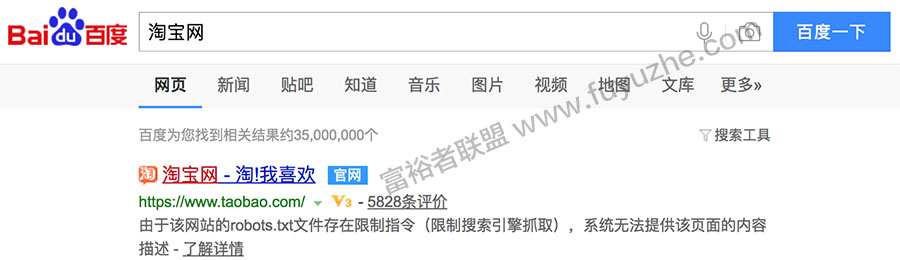
除了可以设置哪些页面可以访问,哪些页面不能访问外。当然你还可以让任何搜索引擎完全不能通过你的网站抓取内容。一般的网站都烧香拜佛希望搜索引擎收录并获得排名,但是也有少部分网站是有足够的底气不让搜索引擎收录的,比如淘宝就明确表明屏蔽百度,淘宝作为国人购物的天堂,域名的易记性和知名度,投广告的资金实力,已经完全无需从百度上获得流量了。
打开编辑器,创建一个新的空白文本文件并将其保存为robots.txt,然后根据需求写入文件:
屏蔽蜘蛛所有页面抓取
User-agent: * Disallow: /
让蜘蛛抓取所有网站所有内容
User-agent: * Disallow:
阻止一些目录抓取
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /personal/ Disallow: /photos/staffchristmasparty/
阻止Googlebot
User-agent: Googlebot Disallow: /
阻止Googlebot意外的蜘蛛抓取
User-agent: Googlebot Disallow: User-agent: * Disallow: /
提示:
- 一条命令写一行,多条命令不能卸载同一行。
- 空白行是间隔一组(如上一个示例所示)。
- User-agent行中的星号在robots.txt中具有特殊含义,不是表示通配符;
- 文件必须一字不差的写成robots.txt,而且是小写的
- 文件必须位于网站的根目录:www.yoursite.com/robots.txt,这是搜索引擎抓取的规范,如果你放错位置,搜索引擎就找不到它。
Robots.txt和您的XML站点地图
很多站长都喜欢生成XML站点地图,这对于搜索引擎确实是好的,但是大部分人都没有在robots.txt做这一步:
Sitemap:
如果你的站点有多个地图,可以这样写:
Sitemap: Sitemap: Sitemap:
这样你就不需要去提交XML站点地图给搜索引擎。搜索引擎会在robots.txt文件时立即找到,机器人在访问您的网站时都会执行收录XML操作。
并不是所有的蜘蛛都遵循robots.txt标准
主流的搜索引擎是遵循robots.txt规范标准的,不会索引您在robots.txt文件中列出的项目。但是,并不是所有的搜索引擎都是按照这个规范索引的(比如,一些小的搜索引擎或一般数据抓取机器人),它们会收集网站所有的内容。
您的robots.txt可以公开访问!
不要尝试使用robots.txt文件来隐藏您网站上的内容 – robots.txt文件可以被任何人查看,只需在浏览器中输入www.yoursite.com/robots.txt即可看到你不想索引的东西!
如果您的网站上有内容真的真的不想让任何人看到,最好的办法是密码保护该目录。比如用一个工具来帮助您在托管控制面板(cPanel或类似软件)中执行保护操作。但是,富裕者联盟并不建议你这么做。